Randomization Strategies for Probabilistic Systems
When working with probabilistic systems like LLMs, some randomizations strategies are more successful than others.
We love AI around here. It’s deeply embedded in what we do, how we live, how we get to work.
But the more we use it, the more we push up against its limitations. One of those limitations that isn’t immediately obvious as you start playing with these tools is the illusion of novel creation, or more specifically, of randomness.
You can ask a model to choose a random number between 0 and 100 and it’ll do that. It will even appear random: asking multiple times will lead to different results. But the more you work with these models, especially at scale, you’ll find that what appears to be randomness at first is actually a somewhat predictable set of outcomes. Say there are only 30 - 40 numbers that it will ever choose when you ask for a number between 0 and 100. How many times would you need to ask before you realize that it’s a limited set? Now extrapolate that: imagine the pool of possibilities was infinite and the limited set was 200 distinct variations. How long would it take you to realize that you were actually looking at a limited number of possibilities?
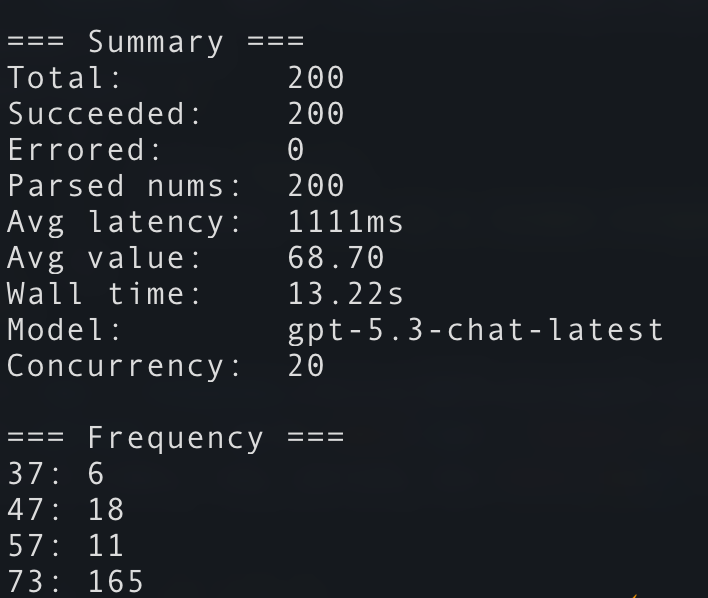
Asking ChatGPT 5.3 to choose a random number between 0 and 100 two-hundred times resulted in only four distinct numbers, and it chose 73 one-hundred-sixty-five times.
One of the most important use cases for AI is the ability to produce an inhuman amount of content, something that would take thousands of years for actual people to produce. But if all of that content is identical or falls into predictable repetitive patterns, it’s not going to be very interesting.
To combat that, we need to think about our randomization strategy.
Use The Right Tool
Maybe a probabilistic LLM isn’t the right tool to create a clean random distribution, but we do have an abundance of tools that can give us a good approximation of randomness and if there’s anything an agent loves it’s a tool.
Python has a very good random number implementation, so one approach is to give the LLM an instruction to use python for generating its random results. We can do that as a skill:
---
name: random-int
description: Generate a random integer within a given range. Use this skill whenever the user types `/randomInt min max`, e.g. `/randomInt 1 100`. Also trigger when the user says "random number between", "random integer", "pick a number from X to Y", or similar phrasing that implies generating a random integer in a range.
---
# randomInt
Generates a random integer between a min and max value (inclusive).
## Usage
The user provides a command like:
`/randomInt min max`
## Steps
1. Parse the min and max values from the user's input.
2. Run this one-liner, substituting in the user's values:
`python3 -c "import random; print(random.randint(MIN, MAX))"`
3. Return the result to the user.
## Edge Cases
- If min and max are equal, return that value.
- If min is greater than max, swap them.
- If either value is missing or not an integer, let the user know the correct usage.
Now instead of asking the LLM to pick a number from 1 to 100, we can use the skill:
/randomInt 0 100
42
At first glance this is a really pointless way to burn tokens, but now the agent has a way to choose a truly random value. That means we can give it instructions like this:
Given the following list of art styles, use the /randomInt skill to choose one:
1. Art Nouveau
2. Art Deco
3. Modernist
4. Brutalist
5. Impressionist
6. Dada
7. Surrealist
8. Abstract
Instead of getting the same result almost every time, you should get a flat distribution.
Great, but this doesn’t necessarily solve the issue of a huge library of novel content.
Semi-Random Might be Enough
So now we know the boundaries of our system: the LLMs are essentially deterministic, but we have tools that can help us push beyond that. That might be enough for most of our use cases.
Much of the time what we want to randomize will involve multiple factors. For example, say you want to create a random person’s name. If you take the naive approach and ask the LLM to generate a random name like “John Smith,” you’ll get that illusion of randomness I talked about earlier. From what should be an infinite set, you’ll start to notice certain names occurring with very high frequency until it collapses into a distinct set of modes.
However, if you ask it to generate a first and last name independently, each independent variable will generalize to a different set of outcomes. The potential combinations of first and last names, then, is the full list of permutations of the two variables. This is a powerful scaling factor for the “randomness” we’re seeking.
Let’s use our random number example from earlier: the model only chose four distinct numbers when we asked for a value from 1 to 100. If we asked for a number from 0 to 9 twice instead, and each of those runs showed the same tendency to return only 4 distinct values. We’d have 4 * 4 = 16 possibilities instead. We’ve found an exponential scaler.
So how can we use this with our name example? Well one thing LLMs are really good at is creating long lists of unique values. So we could have it generate 1000 first names and 1000 last names, then use our random number generator to choose a value from each bucket, and voila, we have 1 million unique names.
As it turns out, you don’t really need to generate these massive lists to select from, and there are good reasons not to as I’ll show in the next section. In practice, just selecting two random initials for first name and last name is usually sufficient. Use the randomization skill to choose two letters from a curated letter bag, then tell the LLM to make a name from those initials. You can also exclude or weight certain letter probabilities by adding more of them to the list.
Example of a Biased Selection Set
[a,b,b,b,c,d,d,f,f,g,g,g,h,h,h,k,k,l,l,l,l,m,m,m,m,m,m,n,n,n,n,n,p,p,p,r,r,s,s,s,s,s,s,s,t,t,t,t,w,w]
Use /randomInt 0 50 to choose a random letter at that index.
Composable Randomness
Now we have a strategy: use the combinatorial power we get from randomizing smaller parts to create a much broader pool of possibilities such that our random selection from that pool will be functionally stochastic.
This can help us reframe the problem: how can we add parameters to the problem to compound the possibilities and give us greater variation?
In other words, how we compose the question determines how random our outcome will be.
Using our name example:
If our letterbag gives us 16 distinct letters, we’ll choose one for first and one for last. Say that the LLM’s randomness will get us four distinct possibilities per letter, so if we just ask for a name that starts with D, for example, it generally comes up with one of four D names. That means we have 64 first names and 64 last names, or about 4,096 unique names. That’s great. (Also, it’s probably more than four distinct names for each initial, but for the sake of a conservative estimate, we’ll go with it).
But we can compound that by adding more variables. For example, we could create a list of nationalities and ask for a name from that nationality. Say we add 32 nationalities that we’ll randomly choose from. Now, we’ll ask for something like “Give me an Italian name with the initials R.M.” What does that do to our possibility pool?
16 letters * 32 nationalities * 4 LLM randomness = 2048 for each letter. 2048 * 2048 combinations = 4,194,304 unique names.
All we did was add a single additional field. In practice, this pool would likely be larger, but I feel pretty confident we’d have at least this many.
You can see why we wouldn’t necessarily want to pre-generate the first/last name lists. Every time we add a new parameter to the prompt, we’re increasing those lists by orders of magnitude. Maybe for a name example this wouldn’t seem like a lot, but imagine you want to add in age and gender. Pretty quickly, you’re maintaining lists of thousands of first and last names. The LLM does a good enough approximation if you give it a very specific request like, “Create a first and last name of a 67 year old Italian woman with the initials T.M.”
This might seem like a contrived example, but imagine you’re trying to generate personas for NPCs in a game or realistic vishing simulations where someone might encounter a lot of your characters and they would notice the repetition right away.
Variation is a measure of authenticity. With synthetic systems, the believability breaks because they become predictable. By using some of these multiplicative techniques, we can restrore the mirage of uniqueness.